
#python #pydantic #dataclasses
Data Classes in Python
You’ve probably found yourself passing dictionaries or tuples around your codebase just to bundle some data together. Maybe it started small: a simple user object or a config blob. But fast-forward a few layers deeper into the app, and suddenly, you're juggling nested dictionaries and checking key names like you're defusing a bomb. We don't have to live like that, and this is where data classes come in.
Let’s talk about what data classes are, why they exist, and the three main tools you'll want to pick from in Python: dataclasses, attrs, and pydantic.
What even is a data class?
A data class is just a regular class that’s primarily meant to hold data and not much behavior. Think of it like a typed container for transporting structured information between parts of your system. You’ll often see these as DTOs (Data Transfer Objects) in layered architectures.
Yes, you could use tuples or dictionaries for that. But those fall apart quickly when the project grows. They’re less readable. They don’t play well with type checkers. And they’re more error-prone. Good luck catching data["nam"] instead of data["name"].
We want structure, type safety, and just enough boilerplate to not hate ourselves.
The built-in: dataclasses
Python 3.7 introduced the dataclasses module: a simple decorator that transforms a class into a lightweight container.
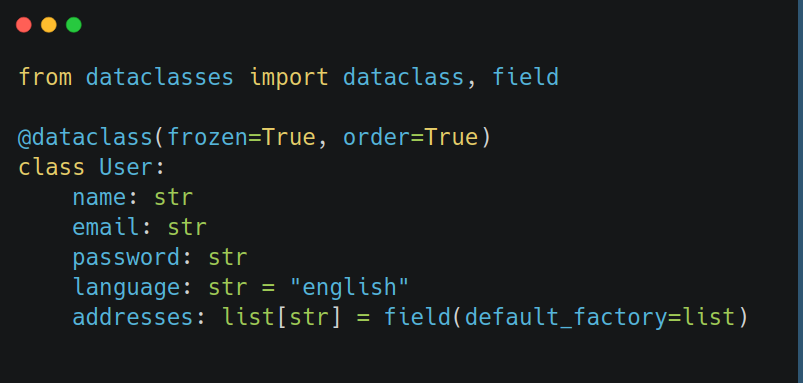
Why is this nicer than writing your own class? Well, for starters, you don’t need to implement a whole bunch of dunder methods such as __init__, __repr__, __eq__, __lt__, etc. On top of that, you get sorting, comparison, immutability (via frozen=True), and default values for free. It’s just a lot cleaner. Say goodbye to repeated, error-prone boilerplate.
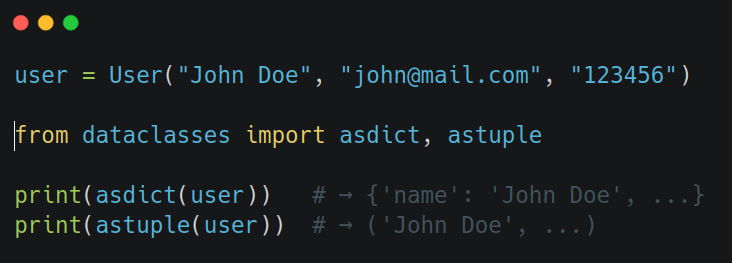
Creating an instance of a dataclass is nothing fancy. And you can get it back as a dict or a tuple:
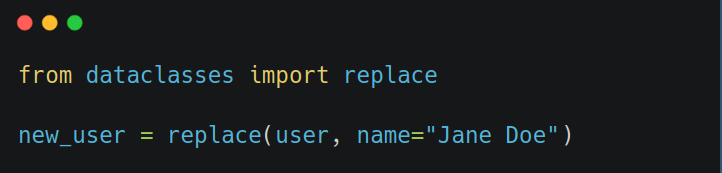
If you need to “change” an immutable instance:
A couple of tips:
- Be careful with mutable defaults, like lists. Always use field(default_factory=...) instead of field(default=...).
- Use kw_only=True to force keyword-only arguments. It prevents accidental bugs with positional ordering.
The inspiration: attrs
Before dataclasses was official, there was attrs. You install it with pip install attrs and import it as attr. It’s a battle-tested library with years of real-world use, and dataclasses was heavily inspired by it.

That should look familiar by now. But there are a few key differences compared to dataclasses.
Attrs supports runtime type checking and conversions, which is an optional yet powerful feature. It also provides more field-level control: validators, converters, hooks, and serialization tweaks. It defaults to slots=True behavior, which is faster and more memory-efficient. And, you don’t need to wait for Python upgrades to get new features; it has its own versioning, being a third-party package.
You can also use the modern @define syntax instead of @attr.s, which plays nicer with tools like mypy. I used the older syntax in the above version because that's what it looked like the last time I used attrs, and it's how you're still more likely to come across it in the wild. Which leads me to an important point: despite attrs being, I believe, a very good package (I have almost no complaint against it), I find myself always gravitating towards either the built-in dataclasses or pydantic instead.
We'll get to pydantic later, but let's talk about when you would reach for attrs over dataclasses. I think it comes down to these 4 reasons:
- When you want richer validators and stricter behavior
- When you need type enforcement or runtime checks (via validators.instance_of or attrs-strict)
- When you’re working in an older Python version (<3.7) where dataclasses isn't available
- When you want to avoid subtle attribute typos and dynamic assignment (__slots__ was added to dataclasses too since 3.10, but doesn't default to True)
The validator king: pydantic
If dataclasses and attrs are about structure, pydantic is about validation and coercion. It’s the go-to tool for APIs, JSON parsing, and external data ingestion. You’ll run into it the moment you touch FastAPI.

What sets pydantic apart is that it parses JSON/dicts effortlessly and coerces types ("5" → int(5), "true" → bool(True)). It also auto-generates schemas, and integrates so well with FastAPI. You just have to mark a FastAPI route function as receiving and returning a pydantic object, and everything just magically works as you'd expect.
An understated benefit is also the intuitive error messages when something fails in the validation. And it supports nested models, aliasing, constraints, pre/post validators, etc. I am yet to run into a use case where pydantic can't get the job done.
We saw above that we can use attrs too, to enforce runtime type checks. But it requires some setup (boilerplate code, or introducing another third-party package). Pydantic does this out of the box. It integrates nicely and cleanly with Python type hints and mypy. While you can achieve type enforcement with attrs too, pydantic is just better at it. Pydantic is a clear winner here because it doesn't introduce any extra syntax. Instead, it leverages Python's built-in type annotations. So when you would annotate an object anyway (for readability, documentation, static type checking), now you get for free also runtime type checks for it. Simple as that.
Performance-wise, though, pydantic has historically been slower than dataclasses/attrs, though V2 (rewritten in Rust) fixed a lot. If you're new to pydantic, stick to V2, no need to mess with the previous version. And for most intents and purposes, the argument of performance would be negligible. There are cases where it would make a difference, but in that scenario, you probably have bigger questions to ask yourself rather than which package to use for DTOs.
Of course, it goes without saying that you wouldn’t introduce pydantic for simple internal data classes. And the same goes for attrs; simply use the built-in dataclasses module for that. Adding a third-party package always comes with its own drawbacks and should be reasonably justified.
You could also mix different tools in the same system. I've seen layered architectures where pydantic is preferred for the edges of the system (HTTP request/response bodies), where more validation is required, and the built-in dataclasses in the data layer at the heart of the system. While I can understand why that approach is followed, personally, if I were to introduce pydantic to a project, then all data classes would be pydantic classes. It's less cognitive effort and more consistency.
When should you use which?
The choice isn't always that clear. There is quite some overlapping scope between the tools, and it depends on how complex your use case is, how big your project is, what framework you are already using, and a plethora of other reasons. Hopefully, the cheat sheet below can help make that decision easier:
| Feature | dataclasses | attrs | pydantic |
|---|---|---|---|
| Built-in | ✅ | ❌ (pip) | ❌ (pip) |
| Validators | 🚫 | ✅ | ✅ |
| JSON Parsing | 🚫 | 🚫 (via cattrs) | ✅ |
| Type Coercion | 🚫 | 🚫 | ✅ |
| Performance | ✅ | ✅ | ⚠️ (slower pre-v2, use only V2) |
| Immutability | ✅ | ✅ | ✅ |
| External inputs | 🚫 | 🚫 | ✅ |
| Version control | ❌ (tied to Python) | ✅ | ✅ |
Use dataclasses when you want structured, typed data containers and you’re on Python 3.7+.
Use attrs when you want more control, stricter behavior, or need to support older Python versions.
Use pydantic when your data is coming from the outside world (especially JSON or API inputs) and you need strict type checking, general validation, and coercion. Or when you're in doubt which tool to use..
Conclusion
So, that's data classes in Python. You could use various tools for the job, and each one has its place. It's honestly hard to go wrong with any of them. The fault, perhaps, lies in not using any: we don't have to pass around naked dictionaries and untyped data structures in modern Python. We thankfully have the means to do much better.