
Working With UUIDs
If you've worked with distributed systems or needed globally unique identifiers, the chances are you've probably encountered UUIDs at some point. This article will dive into what they are, how they work, and when you should (or shouldn't) use them. It's just a grouping of essential notes I've jotted down about UUIDs through the years.

What's a UUID?
A UUID (Universal Unique Identifier) is fundamentally a 128-bit number. That's pretty much it. But since nobody wants to deal with massive numbers, we typically represent UUIDs as 32 hexadecimal characters, grouped with hyphens for readability:
123e4567-e89b-12d3-a456-426614174000
The UUID above is the 128-bit number 24249434048109030647017182301789831168. Each hex character in a UUID represents 4 bits, so 32 hex characters give us our full 128 bits. The hyphens are just for human readability; they don't affect the value.
UUIDs and Distributed Systems
Let's address, using a very simple example, why UUIDs are so popular among distributed systems.
Let's say you're building an e-commerce platform. You have multiple servers across different regions, each handling thousands of orders. When a customer in Tokyo places an order at exactly the same millisecond as a customer in New York, both servers need to generate a unique identifier for these orders.
In a traditional setup with sequential IDs, you'd need these servers to constantly communicate with each other or a central server to ensure they don't issue the same ID. This communication takes time and can fail. What happens if a server can't reach the central ID generator? Should customers wait? Should we risk duplicating IDs? Sequential IDs would introduce a lot of complexity.
This is where UUIDs shine. Each server can generate UUIDs independently, without any communication, and still be practically guaranteed that they won't create duplicates. A server in Tokyo can generate a UUID for an order without checking what IDs the New York server is generating. This independence is crucial for building reliable and scalable systems.
UUIDs in Python
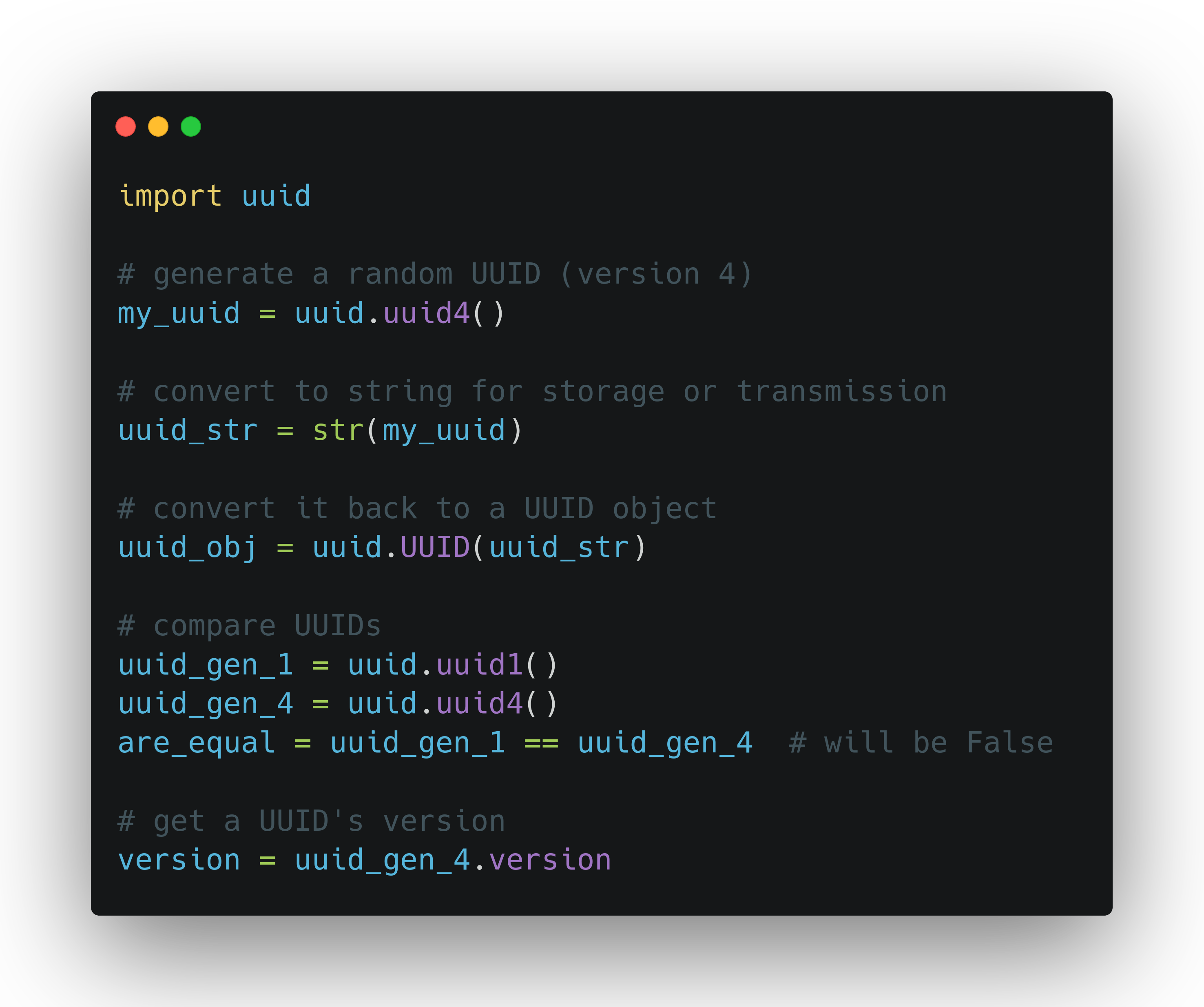
UUIDs are a general concept you can use in all the mainstream programming languages, and there's likely a built-in or third-party package to support that. Python makes working with UUIDs quite straightforward through its built-in uuid module:
UUID Versions
There are several UUID versions/generations, each with its own generation method and use case.
Version 1 is time-based. It is generated using the current timestamp and the computer's MAC address. While this ensures uniqueness, it has privacy implications; you can trace it back to the generating machine and timestamp. It's like leaving breadcrumbs.
Version 4 is randomly generated. It is the most widely used version. It's generated using random or pseudo-random numbers, making it unpredictable and private. This is usually what you want unless you have specific requirements.
Other versions exist (like 3 and 5, which are namespace-based) but they are less commonly used in practice.
UUID Collisions
"But wait," you might say, "if Version 4 UUIDs are random, couldn't they collide?"
Theoretically, yes. But let's put this in perspective: if you generated 1 billion UUIDs per second and kept doing this for 100 years, the probability of a collision would still be very low. The total possible range of unique values is 2^122 (not quite 2^128 due to some version bits). For practical applications, you can safely assume you'll never run into a collision with Version 4 UUIDs.
When Should You Use UUIDs?
UUIDs sound pretty great, so let's use them for everything, right? Interestingly enough, UUIDs aren't always the best choice, and it's important to understand the trade-offs.
We've already touched upon their benefits. It can briefly be distilled into these points:
- globally unique without coordination
- perfect for distributed systems
- can be generated anywhere without central coordination and with little cost
- no information leakage (with Version 4)
But, there are also subtle disadvantages that may be important in certain contexts:
- they take up more space than sequential IDs
- they are less efficient for database indexing
- they're not as human-readable as sequential numbers
UUIDs vs Other Identifier Types
Sequential IDs, as already mentioned, are one alternative. They're usually good enough for single-database applications, where you need simple, efficient primary keys. However, they become problematic in distributed systems where multiple nodes need to generate IDs independently, for reasons already explained above.
Hash-based IDs are another alternative. While some UUID versions (3 and 5) do in fact use hashing, general-purpose hashing is better suited when you need a consistent identifier based on content. Remember that in hashing, the same input always gives the same hash, which might not be what you want for unique identification.
Here's a quick cheat sheet that I use to help me decide.
Choose UUIDs when:
- you're building distributed systems
- you need IDs that can be generated independently
- global uniqueness is more important than storage efficiency
- you want to avoid coordination overhead
Go with alternatives when:
- you're working with a single node/database
- storage space is at a premium
- you need human-readable IDs
- performance is critical and you need the most efficient indexing
As the mantra goes, there's no one-size-fits-all solution. The best choice will always depend on your specific requirements, system architecture, and constraints.