
Caching in Python
In this article, we're going to write a simple caching mechanism in Python from scratch. The goal is to go over the most important concepts related to caching, and see how close we can get to mimicking existing caching solutions. It should also serve as a good exercise of our Python skills. Let's get on with it!
(This is the image Stable Diffusion produced when prompted for "software engineering caching" by the way...seems about right.)
What exactly is caching
Probably everyone of us has a good general understanding of what caching means, but let's drive the concept home with an example I'm quite fond of. You have a working desk, on which your phone, its charger, a pen, headphones, a notebook, and other utility items reside. You also have a cabinet drawer somewhere in the house, where you may store clothes, food, tools, sport gear etc.
Why do you need a desk at all ? It takes up extra space, when you can just store everything in the drawers. Well, here's the thing: the items that you put on top of your desk are more frequently used. You likely use your phone charger every single day. It would be costly and impractical to have to search for it in some miscellaneous drawer every time you need it. So you keep it on your desk, and the desk is a cache for the cabinet drawer. Even though the desk is expensive to buy and takes up space, the convience it provides outweighs the costs. It keeps the important items close to you and easily available.
Likewise, in the world of computing, caching is a technique used for storing the result of computationally-expensive operations somewhere close, so that when you need that result again, you can look it up and not re-compute it. Note here that a computationally-expensive operation isn't just a heavy database query that takes a whole minute to execute. It can even be a function that executes in 100ms, but it's called millions of times.
Another area where caching shines is shared computations. Let's suppose we need to print out the first 100 Fibonacci numbers. Well, fib(100) is a superset of fib(98) and fib(99), which were already computed on their own, as we needed to print them out.
And fib(99) on its own is a superset of many computations that were already done to print out previous numbers. And so it goes on recursively, down to the last number every time. But, if we had cached a call to fib(x), then fib(100) would consist of just one computation: that of summing up the previous 2 results, which are cached at this point and dont need to be re-computed.
Data structure of choice
Our custom cache, as any cache, would hold data. As such, we need to consider what would be the best fitting data structure to hold this data. But before doing that, we must understand the shape and nature of the data that we will store in it. Above we answered the question of when do we usually cache; when a certain operation is resource-intensive and/or frequently demanded. But we didn't address what exactly do we cache. That would usually be the result of a function call. You may rightfully bring up that the bottleneck could lie elsewhere: a stored database procedure, object creation, outside service, or something else. And function calls aren't the only thing that can be cached. But we can still wrap the operation that needs to be cached, in a function call of our general-purpose programming language of choice (i.e. Python). So, to not make things overcomplicated, our solution will need to map function calls, to the result they return. This is a natural key-value arrangament, so we can start with a standard Python dict as the data structure to store the data.
Functional requirements
First of all, our cache dict needs to be available and easily accessable by any part of our Python back-end service. To achieve this, we can take advantage of the Global Object creational pattern. This is a very popular pattern in Python as it fits quite nicely with Python's import system. Python modules are singletons, and defining an object as global (i.e. being created outside of a function or class definition) means it will effectively be created only the first time a module is imported, and cached on every subsequent import. Note that the object can still be mutated anywhere in the codebase, but that's alright for our purposes. In fact, it's what we actually want, as the cache dict should be updateable from anywhere. What we gain from Python's import system, is that the object is not re-created on every import. That would be a very bad thing for us here, as the cached data would be randomly lost, and the cache mechanism would not be stable or reliable. Instead, we want the data to persist in memory for as long as the Python process is still executing, or until we explicitly evict or invalidate the cache.
Next, we need to define how the rest of the codebase will interact with the cache. Of course, every function that needs to read from the cache or update it, can directly access the global dict object that our caching.py module will expose. However, there's some repeated logic that every function needs to perform when accessing the cache, such as checking whether an entry already exist, and/or whether it is still valid (more on this later). For this reason, it makes more sense to wrap this logic in a @cache decorator in a new caching.py module. The logic is centralized, making it easier to maintain, and every function that needs to be cached, can simply be decorated with it. This makes for a cleaner interface.
Our caching mechanism must also differentiate between calls with different arguments of the same function. The obvious reason being, different argument values most likely lead to different result, and the result is what we ultimately want to cache. And, we must of course differentiate between calls of different functions, which happen to receive the same values as arguments. This means each of these function calls must be a separate entry (i.e. key) in our cache:
my_func("a", "b")
my_func("a", "c")
other_func("a", "b")
Initial implementation
Alright so let's create a caching.py module, expose a global CACHE dict object, and create a @cache decorator function:
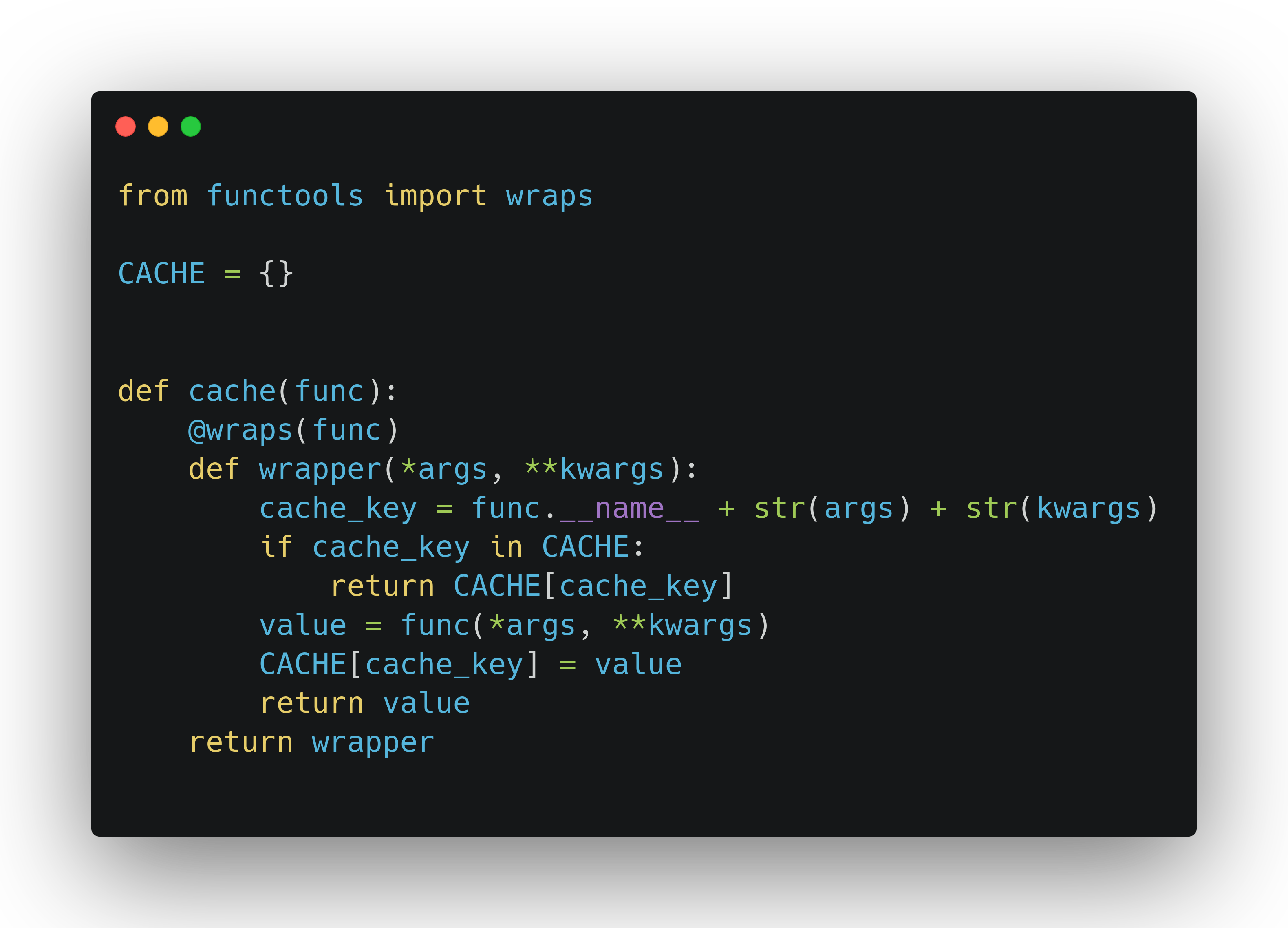
As you can see, this is a pretty standard Python decorator. As usual, we are using @functools.wraps to not lose any metadata (such as signature, docstring etc.) about the function that is being decorated. We're also passing in *args and **kwargs, as our decorator needs to be flexible enough to cater to any function that needs it. Inside the wrapper, we are verifying if the key exists or not in the CACHE dict. If it does, we return the value right away. If not, we call the decorated function, and insert the entry in CACHE. The key is a string comprised of the decorated function's name, and its args and kwargs. The value can be of any type, depending on the function at hand. We take advantage of Python dicts being flexible enough to allow any type as the value.
Usage and tests
Let's use it and verify that it actually works. In a new module named testing.py, we can import the cache decorator and use to decorate a new find_sum() function. This demo function will simply sum up two arguments and return the value. Before doing that, it will print something to the screen, so that we can verify whether it was called or not. After defining it, let's call the function multiple times to simulate different scenarios.
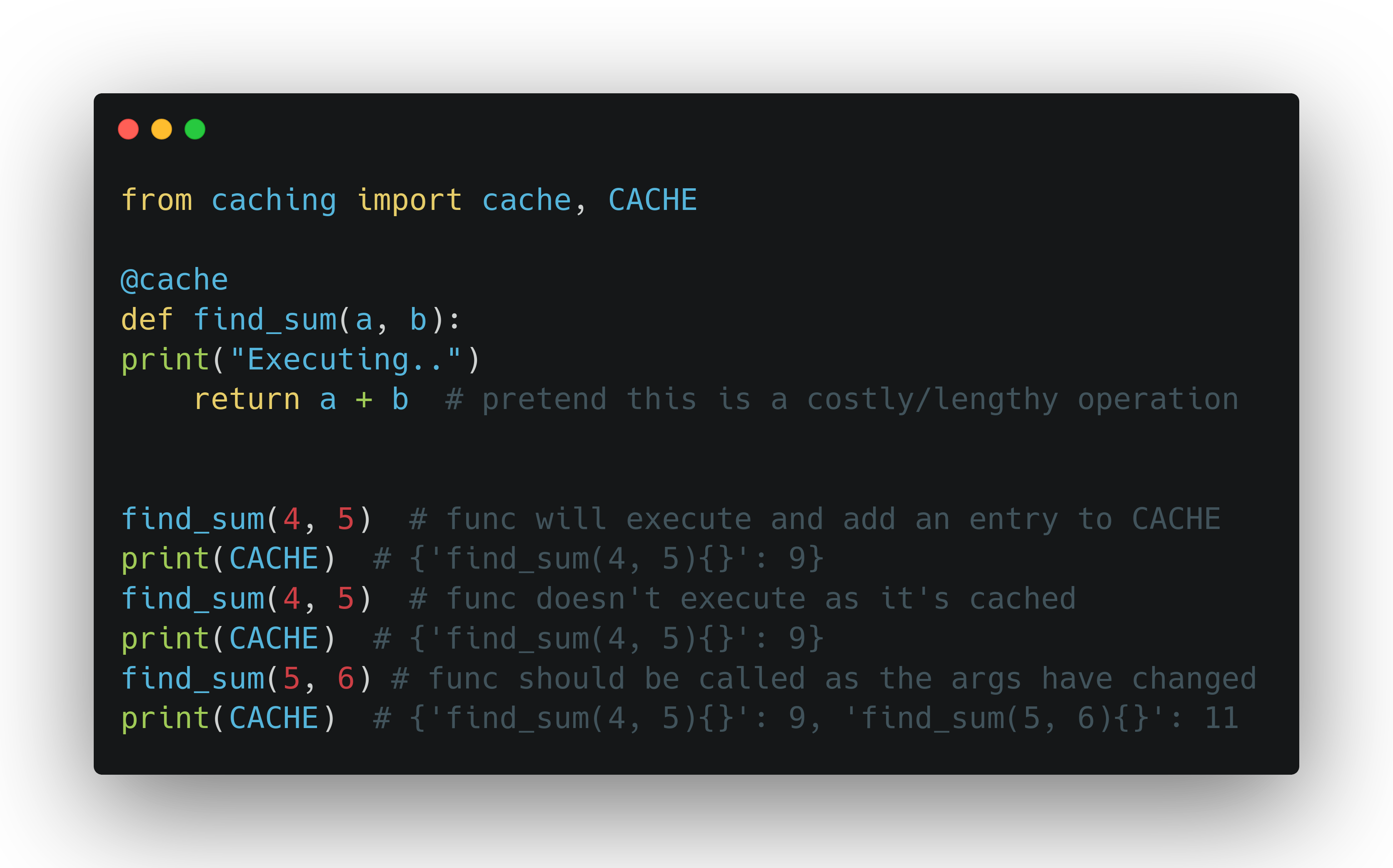
As you can see, everything works as expected. It must be noted that we're only importing CACHE so that we can see its state during execution. Normally, we'll never need to directly interact with it; the decorator does all the work for us.
Timed cache
Our solution is already looking pretty good, but there's one problem with it: the cache never invalidates. This means that after a function call and its result are cached once, they will stay there for as long as the Python process runs. This is not a problem if we're only caching pure functions (such as our find_sum() example above), where for the same input, the result will always be the same. But in a back-end service, you may likely also want to cache the result of functions which read some state (from a database, file, other objects etc) and that state affects their output. In this scenario, caching a function call forever would result in no longer valid or relevant results. Caching can be a double-edged sword as what we gain in performance, we lose in consistency.
To address this concern, it's often necessary to have a cache invalidation policy in place. Cache invalidation is a broad topic in CompSci, and a more difficult problem to solve than what it sounds like. There's many invalidation techniques that can be used. For our example, we will go with the popular solution of invalidating the cache entries after a certain period of time. We will implement a solution that allows us to pick the validity period at the moment of decoration. This will give us more granular control than, let's say, having every cache entry become invalid by default after a static period of time (i.e. 30 minutes). This is quite beneficial, as different parts of our codebase can have different caching needs, and can live with different trade-offs between performance and consistency.
Let's go back to our caching.py module and create a new @timed_cache decorator function based on the existing one:
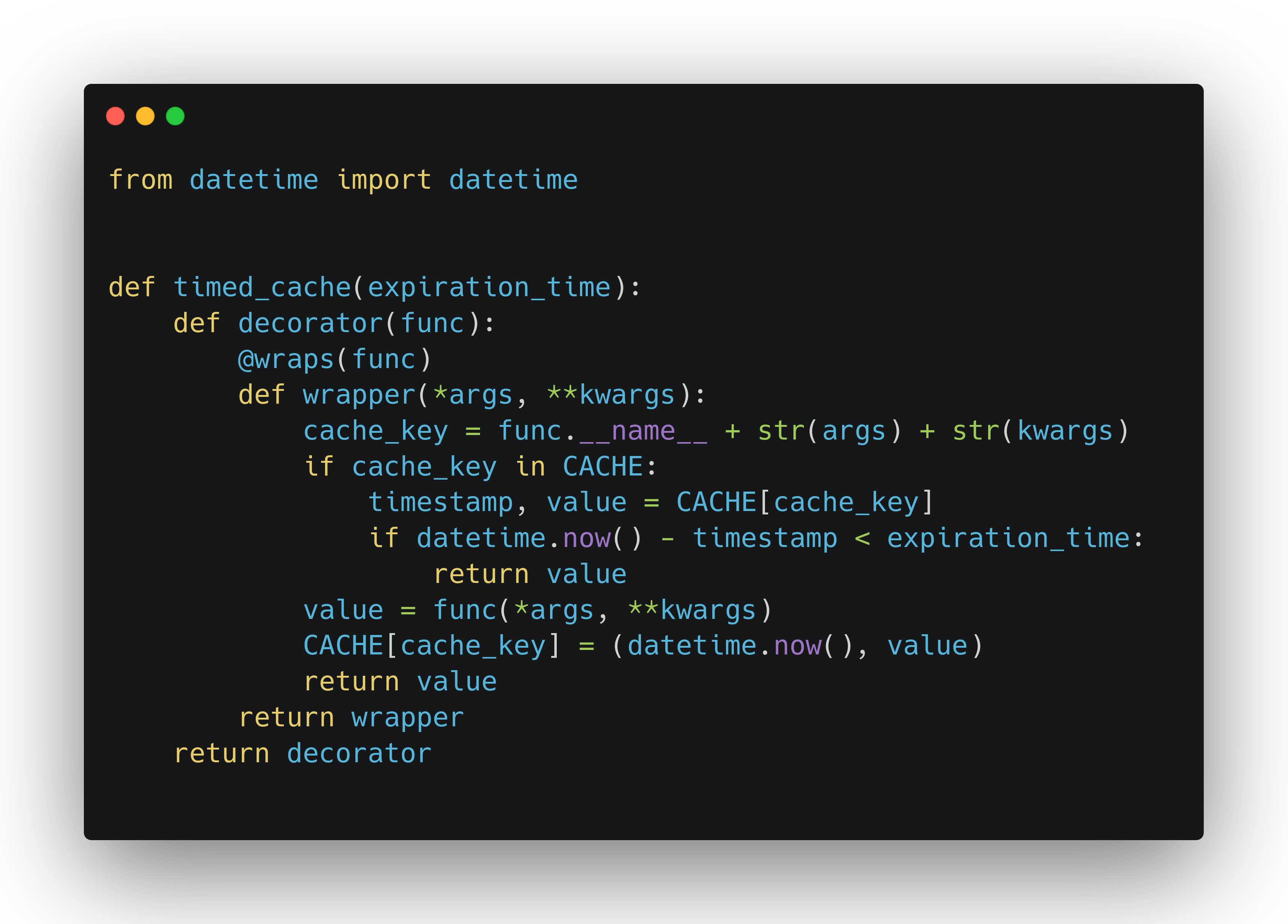
The first thing we can notice here is that the structure is a bit different now. We have two levels of nesting, as we need an additional one to take in the parameter. It's confusing to read, but that's just how decorators work in Python. The outer-most function simply declares the expiration_time parameter and keeps it in the closure. It's the first nested function (i.e. decorator) that actually receives the function to be decorated, and returns it wrapped up with the caching logic. Without diving deeper into decorator internals here, let's just say that this is the price we pay to have expiration_time available in our caching logic.
Speaking of that, there's some tweaks there as well. Now we don't just check if the key is in CACHE, but we also compare if the caching timestamp is within the expiration boundary. If it is, we return the value. If not, we call the decorated function, and then update the cache with not just the result, but also the current timestamp. So the dictionary value is now a tuple of (datetime.datetime, <function result>) pair. It's a simple implementation, but it works quite well. Let's move over to testing.py again and put that to the test.
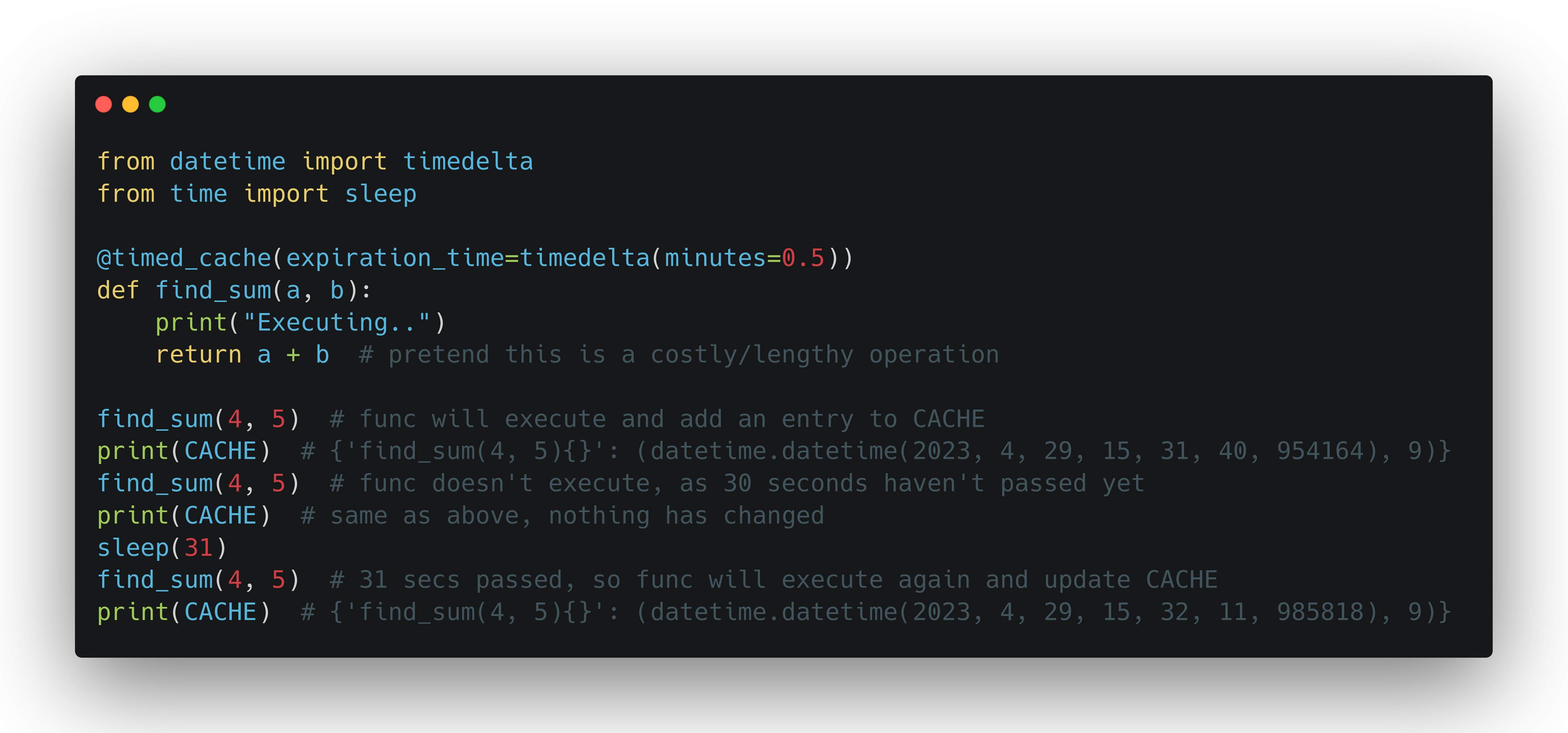
So we have declared our find_sum() function again, but this time it is decorated with @timed_cache and set to expire in half a minute. The first call to it is pretty standard, it simply adds the entry to CACHE. In the second call we get the cached result back, because it hasn't been 30 seconds yet. Then, after we simulate a 30 second delay, the third call to it doesn't pass the expiration check, so the decorated function executes again, and CACHE is updated. You can see that in the final printing out of CACHE. The function result is the same, which is expected of a pure function, but the timestamp is now different, meaning it was successfuly updated. And there we have it, a simple and effective working solution of a timed cache.
Advantages and limitations
Alright, so we built an in-house timed cache in Python. Why would we ever want to do this ? Well, first of all, the introduced complexity is minimal. If you take the initial @cache function out of the picture, as well as the code we wrote to test things out, then we're left with a caching.py module which simply declares a global object and a timed_cache decorator function. That's only 17 lines of Python code in total! And it's a relatively readable and clean solution as well, if you have some experience with Python decorators. Another big plus is that it's agnostic about web frameworks, and can work just fine under any Python process. And, it's very easy to use as well; you just have to decorate functions that need it.
Furthermore, we didn't need to install any third-party packages or client library/sdk. We didn't need to spin up a whole other service, and configure the connection and other settings. There's no network calls to retrieve cached results. We avoided quite some complexity while still ending up with a very much usable solution for basic caching needs.
On the other hand, there's some limitations to it as well. The fact that the cached data is just a Python object within our back-end service, can lead to memory consumption problems if the data gets too big. If it was decoupled as a service of its own (which isn't hard to set up), then the two could scale independently. Moreover, as another service, it could also expose some REST endpoints and make itself available to multiple back-end microservices.
And, due to not having a default max caching period, an entry can only be updated, not deleted. In other words, our simple caching mechanism only invalidates, it doesn't evict. This means it can grow indefinitely, which is potentially dangerous.
The solution is also prone to race conditions. To make it thread-safe, we'd need to introduce a locking mechanism to it. That's actually not hard to do; importing threading.Lock and making a few small tweaks should do the trick. But this article is already getting too long, so maybe another time.
On a related note, the solution is not process-safe either. We'd need to use a shared memory object (something from multiprocessing.Manager) that can be safely accessed by different processes. This can have performance implications since it involves interprocess communication, but again it's the price we pay. I will not go ahead and implement this either, although as with threading, it wouldn't require a lot of changes. I'll leave these two safety limitations as an exercise for whoever is reading the post, and perhaps we can cover it in a part 2 of this article, alongside making a REST service out of all of this.
Existing solutions in Python
If you're fimiliar with the functools module, then you're probably aware of @cache and @lru_cache. The @functools.cache decorator is a thin wrapper around @functools.lru_cache, and should be preferred when you don't want to limit the cache size, as a LRU (least recently used) cache without a limit doesn't make sense. You can of course just use `@lru_cache(maxsize=None)` and achieve the exact same functionality, but using @cache makes the code clearer.
If you're caching objects that take up a lot of memory, then capping the max size of the cache is a must though, so you should prefer @lru_cache instead.
How does all of this fit in with our custom code above ? Well, @functools.cache pretty much makes our initial @caching.cache example unnecessary, but it was a good exercise, and we needed to start somewhere, before getting to the more advanced @caching.timed_cache example. Speaking of which, neither of the two decorators that functools provides support time-based invalidation, so it's an example that you may end up actually using. Our custom @timed_cache does not limit the size though, unlike @lru_cache, which is another potential limitation of it, that we briefly touched upon even above.
The functools solutions don't offer thread or process safety either, so in that regard they're not any better than the custom code we wrote.
There's also the cachetools third-party package, which actually does provide a time cached solution, among other caching utilities. Its solutions have been tested and refined more thoroughly than our custom code, so that'd be a big motive to resort to it instead. However, having to add another dependency to your project, when you can achieve what you need with a few lines of custom code, can be a deal-breaker in many circumstances.
Dedicated caching service
Our custom decorators, standard library's functools.lru_cache and functools.cache, and third-party `cachetools` decorators are good choices when you need a simple, in-memory cache for small to medium-sized applications with relatively low traffic. They are easy to use, fast, and require minimal setup. They're viable solutions in many scenarios.
However, if you have a large application with high traffic, or if you need to share the cache across multiple servers or processes, you should consider using a dedicated caching service like Redis. Redis is a popular key-value store that provides advanced features such as distributed caching, replication, persistence, and more. It can handle much larger data sets and it can scale horizontally across multiple servers.
On the other hand, spinning up another service means more development/deployment complexity and costs. Therefore, a dedicated caching service should in general be the last resort, when none of the other solutions work for you.
Conclusion
In this article, we went over what caching is and some basic concepts related to it. We wrote a custom solution for a simple caching mechanism, and compared it to existing solutions in the standard library, third-party packages and dedicated services outside the Python world. There's quite some technical improvements that we can further perform, such as making it a dedicated Python service that exposes some REST endpoints, implementing size and/or timed eviction (besides invalidation), making it thread and process safe, and perhaps even persisting less frequently accessed data to storage. Those would be some good topics to address in a second part of this article perhaps, but I hope this article served as a good starting point to playing around with caching in Python.